

Artikel bijgewerkt door Joel Lee op 10/10/2017
Ontgrendel nu de cheat sheet 'Top Google Search Keyboard Shortcuts'!
Dit zal je aanmelden voor onze nieuwsbrief
Voer je e-mail in Ontgrendel Lees ons privacybeleidVoor veel mensen is Google internet. Het is het startpunt voor het vinden van nieuwe sites en is misschien wel de belangrijkste uitvinding sinds het internet zelf. Zonder zoekmachines zou nieuwe webinhoud ontoegankelijk zijn voor de massa.
Maar weet u hoe zoekmachines werken? Elke zoekmachine heeft drie hoofdfuncties: crawlen (inhoud ontdekken), indexeren (inhoud bijhouden en opslaan) en ophalen (relevante inhoud ophalen wanneer gebruikers de zoekmachine bevragen).
Kruipen
Crawling is waar het allemaal begint: het verzamelen van gegevens over een website.
Het gaat om het scannen van sites en het verzamelen van details over elke pagina: titels, afbeeldingen, sleutelwoorden, andere gelinkte pagina's, enz. Verschillende crawlers kunnen ook andere details zoeken, zoals paginalay-outs, waar advertenties worden geplaatst, of links worden gepropt, enz.
Maar hoe is een website gecrawld? Een geautomatiseerde bot (een zogenaamde 'spider') bezoekt pagina na pagina zo snel mogelijk, met behulp van paginakoppelingen om vervolgens te vinden waar naartoe. Zelfs in de vroegste dagen konden de spiders van Google honderden pagina's per seconde lezen. Tegenwoordig is het in de duizenden.
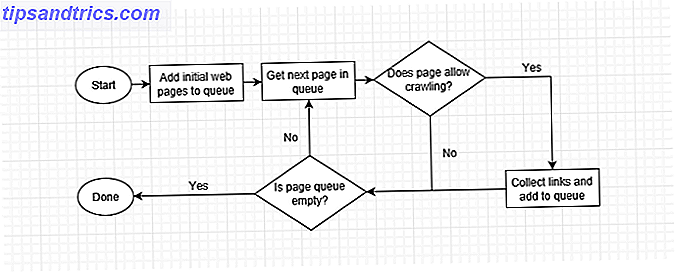
Wanneer een webcrawler een pagina bezoekt, verzamelt deze elke link op de pagina en voegt deze toe aan de lijst met volgende pagina's die moet worden bezocht. Het gaat naar de volgende pagina in zijn lijst, verzamelt de links op die pagina en herhaalt het. Webcrawlers gaan ook af en toe terug naar vorige pagina's om te zien of er wijzigingen zijn opgetreden.
Dit betekent dat elke site die is gelinkt vanaf een geïndexeerde site uiteindelijk wordt gecrawld. Sommige sites worden vaker gecrawld en sommige worden naar een diepere diepte doorzocht, maar soms geeft een crawler mogelijk op als de paginahiërarchie van een site te ingewikkeld is.
Een manier om te begrijpen hoe een webcrawler werkt, is door er zelf een te bouwen. We hebben een zelfstudie geschreven over het maken van een eenvoudige webcrawler in PHP, dus controleer dat als je programmeerervaring hebt.

Houd er rekening mee dat pagina's kunnen worden gemarkeerd als "noindex". Dit is vergelijkbaar met zoekmachines vragen de indexering over te slaan. Niet-geïndexeerde delen van het internet staan bekend als het "diepe web" Wat is het diepe web? Het is belangrijker dan u denkt Wat is het diepe web? Het is belangrijker dan je denkt Het deep web en het dark web zijn beide eng en gevaarlijk, maar de gevaren zijn overdreven. Dit is wat ze eigenlijk zijn en hoe je ze zelfs zelf kunt openen! Meer lezen en sommige sites, zoals die op het TOR-netwerk worden gehost, kunnen niet door zoekmachines worden geïndexeerd. (Wat is TOR en ui routing? Wat is Onion Routing, Precies? [MakeUseOf Explains] Wat is Onion Routing, Precies? [MakeUseOf Explains] Internetprivacy Anonimiteit was een van de grootste kenmerken van internet in zijn jeugd (of een van de de slechtste functies, afhankelijk van wie je het vraagt.) Afgezien van de soorten problemen die voortkomen ... Lees meer)
Indexeren
Indexeren is wanneer de gegevens uit een crawl worden verwerkt en in een database worden geplaatst.
Stel je voor dat je een lijst maakt van alle boeken die je bezit, hun uitgevers, hun auteurs, hun genres, hun paginatellingen, etc. Crawling is wanneer je door elk boek kamt terwijl indexeren gebeurt wanneer je ze bij je lijst aanmeldt.
Stel je nu voor dat het niet alleen een kamer vol met boeken is, maar elke bibliotheek in de wereld. Dat is een kleinschalige versie van wat Google doet, die al deze gegevens opslaat in enorme datacenters met duizenden petabytes aan schijven Geheugen Sizes Explained - Gigabytes, Terabytes & Petabytes in Layman's Terms Memory Sizes Explained - Gigabytes, Terabytes & Petabytes in De voorwaarden van Layman Het is gemakkelijk te zien dat 500GB meer dan 100GB is. Maar hoe verhouden verschillende grootten zich? Wat is een gigabyte naar een terabyte? Waar past een petabyte in? Laten we het opruimen! Lees verder .
Hier is een kijkje in een van de zoekgegevenscentra van Google:

Ophalen en rangschikken
Retrieval is wanneer de zoekmachine uw zoekopdracht verwerkt en de meest relevante pagina's retourneert die overeenkomen met uw zoekopdracht.
De meeste zoekmachines onderscheiden zich door hun ophaalmethoden: ze gebruiken verschillende criteria om te kiezen en kiezen welke pagina's het beste passen bij wat u zoekt. Dat is waarom zoekresultaten variëren tussen Google en Bing, en waarom Wolfram Alpha zo uniek nuttig is. 10 Cool gebruik van Wolfram Alpha als u leest en schrijft in het Engels 10 Cool gebruik van Wolfram Alpha als u leest en schrijft in het Engels Taal Het duurde me enige tijd om mijn hoofd rond Wolfram Alpha te wikkelen en de queries die het gebruikt om die resultaten te verspreiden. Je moet diep in Wolfram Alpha duiken om er echt gebruik van te maken ... Lees meer.
Ranking-algoritmen controleren uw zoekopdracht tegen miljarden pagina's om ieders relevantie te bepalen. Bedrijven bewaken hun ranking-algoritmen als gepatenteerde industriële geheimen vanwege hun complexiteit. Een beter algoritme vertaalt zich naar een betere zoekervaring.
Ze willen ook niet dat webmakers het systeem spelen en oneerlijk naar de top van de zoekresultaten klimmen. Als de interne methodologie van een zoekmachine ooit zou uitkomen, zouden alle soorten mensen die kennis zeker misbruiken ten koste van mensen zoals jij en ik.

Exploitatie van zoekmachines is natuurlijk mogelijk, maar is niet zo eenvoudig meer.
Oorspronkelijk rangschikten zoekmachines sites op hoe vaak zoekwoorden op een pagina verschenen, wat leidde tot 'keyword stuffing' - het vullen van pagina's met zware onzin van zoekwoorden.
Toen kwam het concept van link-belang: zoekmachines waardeerden sites met veel inkomende links omdat ze de populariteit van de site interpreteerden als relevantie. Maar dit leidde tot spammen via links over het web. Tegenwoordig wegen zoekmachines gewichten aan afhankelijk van de "autoriteit" van de koppelingssite. Zoekmachines geven meer waarde aan koppelingen van een overheidsinstantie dan links uit een koppelingsdirectory.
Vandaag zijn rankingsalgoritmen meer mysterieus dan ooit tevoren verborgen, en "zoekmachineoptimalisatie" Demystify SEO: 5 gidsen voor zoekmachineoptimalisatie die u helpen bij het demystificeren van SEO: 5 gidsen voor zoekmachine-optimalisatie die u helpen Begin van de beheersing van zoekmachines brengt kennis en ervaring met zich mee, en veel vallen en opstaan. U kunt beginnen met het leren van de fundamenten en het voorkomen van veelvoorkomende SEO-fouten met behulp van vele SEO-gidsen die beschikbaar zijn op internet. Meer lezen is niet zo belangrijk. Goede zoekmachine rankings komen nu uit hoogwaardige content en geweldige gebruikerservaringen.
Wat is de toekomst voor zoekmachines?
Ah, nu is er een interessante vraag. Het antwoord is "semantiek": de betekenis van de inhoud van de pagina. U kunt meer lezen in ons overzicht van semantische markup en de toekomstige impact ervan. Wat semantische markup is en hoe het het internet voor altijd zal veranderen [technologie verklaard] Wat semantische markup is en hoe het het internet voor altijd zal veranderen [technology explained] Lees meer.
Maar hier is de kern van.
Op dit moment kun je zoeken naar "glutenvrije cookies", maar de resultaten kunnen recepten voor glutenvrije cookies retourneren. In plaats daarvan kunt u regelmatig cookie-recepten vinden met de tekst: "Dit recept is niet glutenvrij." Het heeft de juiste zoekwoorden, maar de verkeerde betekenis.
Met semantiek kunt u cookie-recepten zoeken en vervolgens bepaalde ingrediënten verwijderen: meel, noten, enz. U kunt de resultaten ook beperken tot alleen recepten met prep-tijden van minder dan 30 minuten en scores van 4/5 of hoger bekijken. Dat zou gaaf zijn, toch? Dat is waar we naartoe gaan!
Nog steeds in de war over hoe zoekmachines werken? Zie hoe Google het proces uitlegt:
Als je dit interessant vindt, wil je misschien ook leren hoe zoekmachines werken.
Beeldcredits: prykhodov / Depositphotos